Tensorflow实现手写数字识别
一、程序逻辑总体设计分析
假设我们要建造一个智能机器人,它能够识别不同人手写的数字。
-
首先,我们需要为机器人提供大量手写数字的示例,以便它能学会识别数字。这就是我们的数据集。我们可以选择
MNIST数据集,它包含了大量的手写数字图像及其对应的标签。 -
接下来,我们需要设计机器人的“大脑”,即
神经网络。我们从一个简单的卷积神经网络开始。这个网络由几个“视觉”层组成,用于提取图像中的特征。这些视觉层包括卷积层和池化层。卷积层就像是一组滤镜,可以捕捉图像中的线条、角和其他局部特征。池化层则像是一个缩放镜,它可以缩小图像,让我们能够更有效地关注重要的特征。 -
在这些视觉层之后,我们使用
全连接层来整合所有提取到的特征,将它们组合成一个全局表示。全连接层(或密集层)是一种常用的神经网络层,它将前一层的所有神经元连接到后一层的所有神经元。全连接层可以学习到输入特征之间的复杂关系,并将这些关系整合成一个全局表示。全连接层就像是一个大型“思考”模块,可以理解和解释从视觉层获取到的特征。 -
为了防止机器人在学习过程中过度依赖某些特征(即过拟合),我们添加一个
Dropout 层。Dropout 层被应用于全连接层的输出,以降低过拟合的风险。Dropout 层通过在训练过程中随机丢弃一部分神经元的输出,从而使网络变得更加稀疏,减少对特定神经元的依赖。这迫使网络在学习时更加谨慎,从而提高泛化能力。 -
最后,我们用一个具有
softmax 激活函数将网络的输出转换为概率分布。它接收全连接层的输出,并将每个输出值转换为概率值,使得所有类别的概率之和为 1。这样,我们就可以通过挑选具有最高概率的类别来实现对输入数据的分类。这样,我们就可以让机器人预测它认为每个数字的可能性。 -
现在,我们需要让机器人学习识别手写数字。我们将数据分成
训练集和测试集,用训练集来训练网络,然后用测试集评估网络的性能。这就像是让机器人先观察大量的手写数字样本,然后测试它在未见过的样本上的识别能力。
在训练过程中,我们使用
损失函数来衡量机器人的预测与实际标签之间的差距。我们的目标是最小化这个损失值。同时,我们使用准确率指标来评估机器人的性能。
经过一定轮次的训练,我们的机器人将能够识别手写数字,并在测试集上达到很高的准确率。这意味着它已经学会了识别手写数字的技巧,并且可以在实际应用中辨认出不同人书写的数字。
二、代码
1 | |
三、结果截图
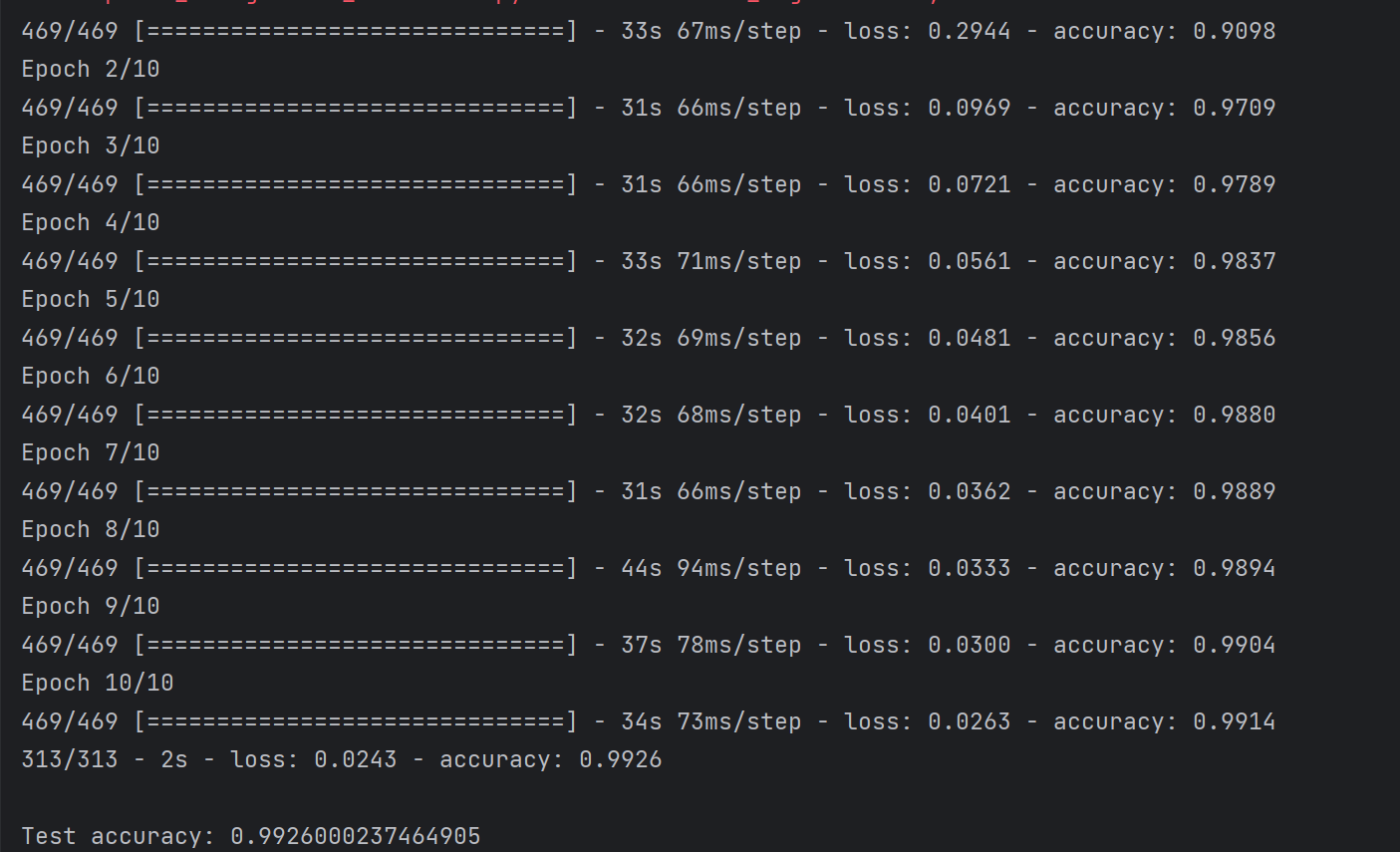
四、程序代码详细分析
4.1 导入所需的库和模块
1 | |
4.2 将 MNIST 数据集加载到内存中,并将其划分为训练集和测试集
1 | |
4.3 将图像数据重新调整为四维张量,并对像素值进行归一化
卷积层需要具有四个维度的输入(样本数量、高度、宽度和通道数)。在这里,我们将图像调整为形状为 (样本数, 28, 28, 1) 的四维张量。
1 | |
4.4 定义卷积神经网络模型的结构
1 | |
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)):第一个卷积层,包含 32 个 3x3 大小的滤波器,激活函数为 ReLU。这一层会学习输入图像的局部特征。MaxPooling2D(pool_size=(2, 2)):第一个池化层,使用 2x2 的窗口对卷积层的输出进行降采样。这有助于减少模型参数数量,降低计算复杂度。Conv2D(64, kernel_size=(3, 3), activation='relu'):第二个卷积层,包含 64 个 3x3 大小的滤波器,激活函数为 ReLU。这一层进一步学习更高级别的特征。MaxPooling2D(pool_size=(2, 2)):第二个池化层,使用 2x2 的窗口对卷积层的输出进行降采样。这有助于进一步减少模型参数数量,降低计算复杂度。Flatten():这一层将卷积和池化层的输出展平为一维向量,以便输入到全连接层。Dense(128, activation='relu'):第一个全连接层,包含 128 个神经元,激活函数为 ReLU。这一层用于学习图像特征的全局表示。Dropout(0.5):一个 Dropout 层,丢弃率设置为 0.5。它在训练过程中随机关闭一部分神经元,有助于防止过拟合。Dense(10, activation='softmax'):最后一个全连接层,包含 10 个神经元,激活函数为 Softmax。这一层用于将模型的输出转换为各个类别的概率分布
4.5 编译模型,为训练过程做准备
1 | |
我们指定优化器为 ‘adam’,损失函数为 SparseCategoricalCrossentropy,评估指标为 ‘accuracy’。
4.6 使用训练数据训练模型
1 | |
设置训练轮次(epochs)为 10,批处理大小(batch_size)为 128。批处理大小决定了每次更新模型权重时使用多少个样本。较大的批处理大小可以加速训练过程,但可能会导致泛化性能较差。
4.7 使用测试数据评估模型性能
1 | |
模型会计算在测试集上的损失和准确率。然后输出模型在测试集上的准确率。这可以让我们了解模型在识别手写数字任务上的表现。
五、参数调整
1. 增加卷积层的滤波器数量:
在卷积层的定义中,例如 Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),第一个参数(32)表示滤波器的数量。可以尝试增加或减少这个值,例如将其更改为 64、128 等。
增加卷积层滤波器的数量意味着模型可以学习到更多特征。 这可能有助于提高模型的性能,因为模型可以捕捉到更丰富的特征信息。然而,增加滤波器数量也会增加模型的计算成本和复杂性,可能导致过拟合。在实际操作中,您需要找到一个合适的滤波器数量,以权衡模型性能和复杂性之间的关系。
2. 修改池化层的大小:
在池化层的定义中,例如 MaxPooling2D(pool_size=(2, 2)),pool_size 参数表示池化窗口的大小。可以尝试更改这个值,例如将其设置为 (3, 3) 或 (4, 4)。
增加池化层的大小会降低特征图的空间分辨率, 从而减少模型的参数数量和计算成本。较大的池化窗口可能导致模型损失部分空间信息,从而影响模型的性能。在实际操作中,您需要根据具体任务和数据集来选择合适的池化层大小,以实现较好的性能和计算效率之间的平衡。
3. 增加训练轮次:
在训练模型的代码中,例如 model.fit(x_train, y_train, epochs=10, batch_size=128),epochs 参数表示训练轮次。可以尝试增加或减少这个值,例如将其更改为 20、30 等。
增加
epochs(训练轮次)会使模型在整个训练集上进行更多次迭代。这可能有助于提高模型在训练集上的性能,但也可能导致过拟合,尤其是当训练轮次过多时。过拟合意味着模型在训练数据上表现得很好,但在测试数据上的泛化能力较差。
4. 更改批处理大小:
在训练模型的代码中,例如 model.fit(x_train, y_train, epochs=10, batch_size=128),batch_size 参数表示批处理大小。可以尝试增加或减少这个值,例如将其更改为 64、256 等。
增加
batch_size(批处理大小)会使每次更新权重时使用更多样本。这通常可以加速训练过程,因为较大的批处理大小意味着每个 epoch 中需要进行的权重更新次数减少。然而,较大的批处理大小可能会降低模型的泛化性能,因为权重更新的频率减少,可能导致模型陷入局部最优解。模型
陷入局部最优解是指在训练过程中,模型的参数被困在某个局部最优点,而无法达到全局最优点。局部最优解是损失函数在参数空间中的局部最小值点,而全局最优解是损失函数在整个参数空间中的最小值点。通常情况下,我们希望模型能够找到全局最优解,以实现最佳的性能。
模型陷入局部最优解可能会影响训练集和测试集上的性能。在训练集上,模型可能无法达到最低的损失值,这意味着模型在训练数据上的拟合程度不够理想。在测试集上,模型的泛化能力可能受到影响,导致在未见过的数据上表现较差。
5. 使用不同的优化器:
在编译模型的代码中,例如 model.compile(optimizer='adam', loss=SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']),optimizer 参数表示使用的优化器。可以尝试替换为其他优化器,如 ‘sgd’、‘rmsprop’ 等。
六、环境配置遇到的问题
6.1 pycharm解释器配置(anaconda虚拟环境)
最新版的pycahrm是让我们找到conda安装文件夹下condabin子文件夹下的conda.bat文件,然后选中,再点加载环境。就会自动找出所有的conda环境。
网上大部分的教程使用的是conda.exe或者_conda.exe,而我在尝试的过程中遇到了pycharm无反应、exe不存在等诸多问题。
在这之后,需要点击pycharm右下角,查看当前所有解释器,然后选择相应的exe文件。
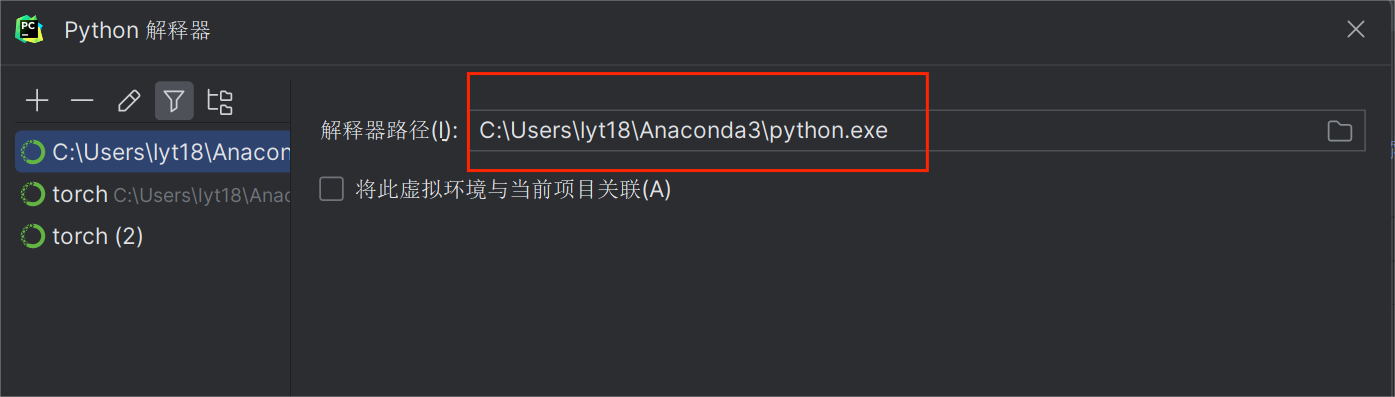
6.2 Cannot uninstall ‘wrapt’
在下载tensorflow的时候遇到如下报错:
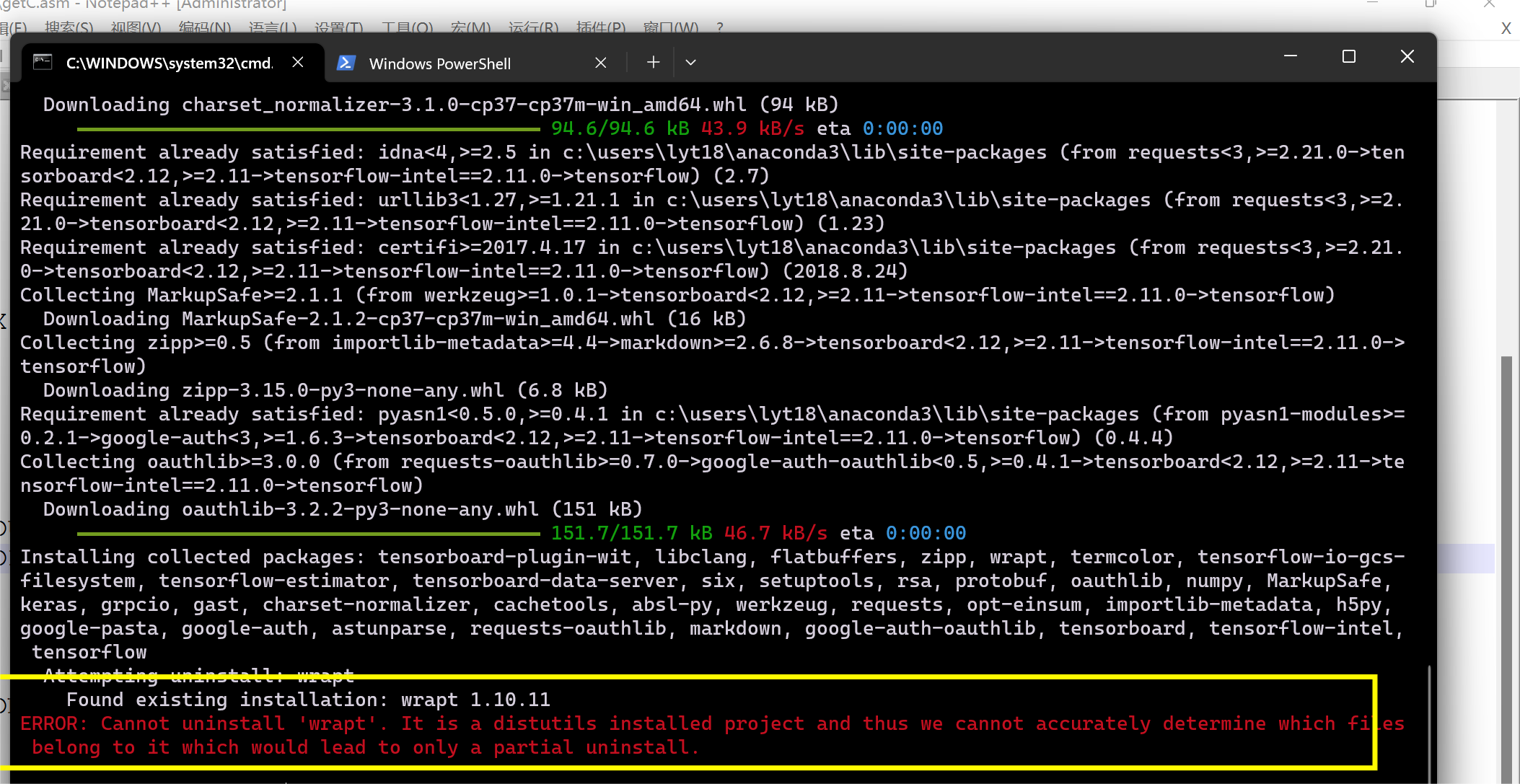
*方法一:使用--ignore-installed选项
在安装TensorFlow时使用–ignore-installed选项,这将忽略已经安装的包,包括wrapt。这意味着pip不会尝试卸载旧版本的wrapt,而是安装TensorFlow所需的新版本。
1 | |
*方法二:使用--user选项
另一种方法是使用–user选项安装TensorFlow。这将在用户的Python库路径中安装包,而不是系统级别的库。这样,即使系统级别的库存在冲突,也可以成功安装TensorFlow。
1 | |
6.3 module compiled against API version 0xe but this version of numpy is 0xd
运行程序时候有报错:
RuntimeError: module compiled against API version 0xe but this version of numpy is 0xd ImportError: numpy.core.multiarray failed to import
错误信息显示模块需要API版本0xe(即API版本14),而我目前使用的NumPy版本是API版本0xd(即API版本13)。为了解决这个问题,应该将NumPy更新至一个支持API版本14的版本。
然后我查找了网上流传的tensorflow+keras+numpy的版本对应表,改安装到对应版本时遇到了报错:
ImportError: Something is wrong with the numpy installation. While importing we detected an older version of numpy in [‘C:\Users\lyt18\Anaconda3\lib\site-packages\numpy’]. One method of fixing this is to repeatedly uninstall numpy until none is found, then reinstall this version.
解决方法:
- 卸载当前已安装的numpy版本
1 | |
可能需要运行几次,直到提示"WARNING: Skipping numpy as it is not installed",说明已卸载所有numpy版本。
- 再使用install语句安装。
但是,仍然存在API版本不对应的问题。后来我抱着试一试的心态,将numpy升级到最新版本,无此报错。 猜测网上流传的表有误。
6.4 PackagesNotFoundError: The following packages are not available from current channels
报错:
Solving environment: failed Packages
NotFoundError: The following packages are not available from current channels: - python=3.6
Current channels: - https://conda.anaconda.org/conda-forge/win-64
- https://conda.anaconda.org/conda-forge/noarch
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/win-64
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/noarch
To search for alternate channels that may provide the conda package you’re looking for, navigate to https://anaconda.org and use the search bar at the top of the page.
不用conda指令,改用pip,十分顺利
6.5 cannot import name ‘OrderedDict’ from ‘typing’
尝试了多种网上的方法,有效的是在第二行添加语句:
1 | |
前提是,我的环境中以有typing_extensions,如果没有,可以尝试将typing_extensions改为typing
(可以在激活环境后,执行conda list语句查看自己虚拟环境中有的包)
6.6 ModuleNotFoundError: No module named ‘keras.api’
尝试了多种方法,成功解决的方案是:
1 | |
也就是,把keras升级到最新版本(2.11.0),而非按照网上流传的对应版本。
最终,对于本实验中涉及到的包和解释器,我的版本表为:
| 名称 | 版本 |
|---|---|
| python | 3.7.0 |
| tensorflow | 2.11.0 |
| keras | 2.11.0 |
| numpy | 1.21.6 |
| pip | 10.0.1 |
| typing_extension | 4.5.0 |
七、实验感悟
-
在配置环境的过程中,我意识到需要非常耐心,仔细检查错误,并针对具体问题进行解决。如果网络上的解决方案都无法解决问题,我可以尝试勇敢地自己创新解决,这对于我的问题解决能力和独立思考能力都有很大的提升。
-
通过学习基础的CNN知识,我在实践中掌握了各个模块的安排顺序,这使得我对这一领域的知识有了更深刻的理解。实践过程中,我逐步熟悉了卷积层、池化层以及全连接层等关键部分的搭建和优化,加深了对神经网络的认识。
-
完成实验后,我认真地撰写了实验报告,这使得我对整个实验过程有了更多的体会。在整理和总结实验过程中,我重新审视了自己在实验中所遇到的问题以及解决方法,这对于巩固所学知识非常有帮助。通过对实验结果的分析和讨论,我体验到了很大的成就感,同时也激励我在未来的学习和研究中更加努力。